A workload management system is helpful to be able to schedule jobs on a cluster of nodes. The steps below describe how to set up Slurm in such a way so that GPUs have to be explicitly requested. This way it becomes much easier to share GPU and CPU compute resources among a large number of people without having users get in each other’s way.
To start the process, we are going to remove the current Slurm setup if there is any, and then start the interactive setup tool:
# cm-wlm-setup --disable --wlm-cluster-name=slurm --yes-i-really-mean-it
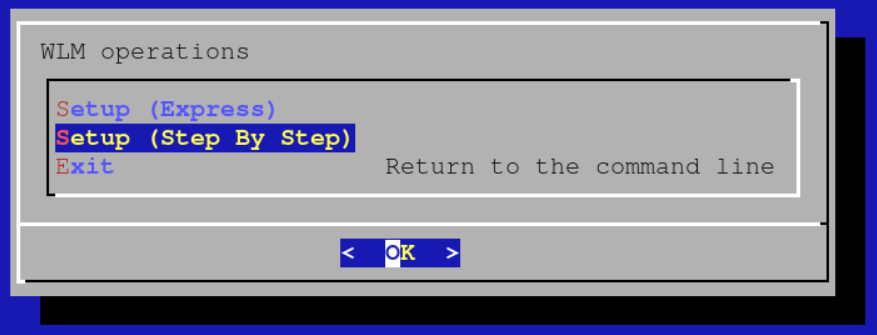
# cm-wlm-setupChoose the Step By Step setup option:
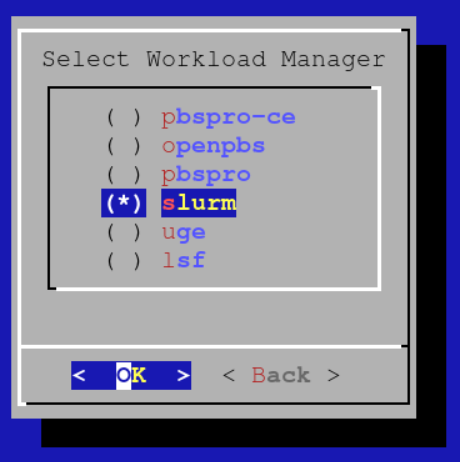
Select Slurm as the workload management system to set up:
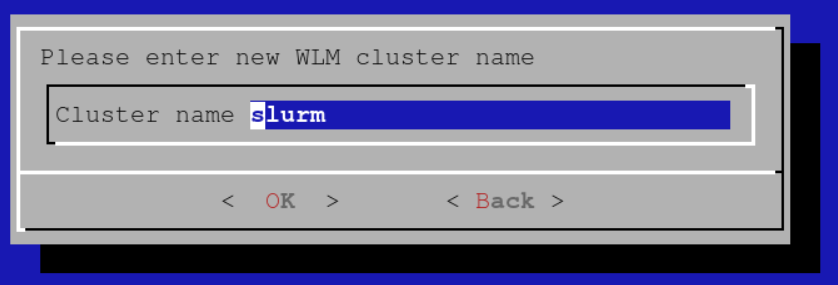
Set an appropriate name for the Slurm cluster (slurm will do fine if you will only have one Slurm instance on this Bright cluster).
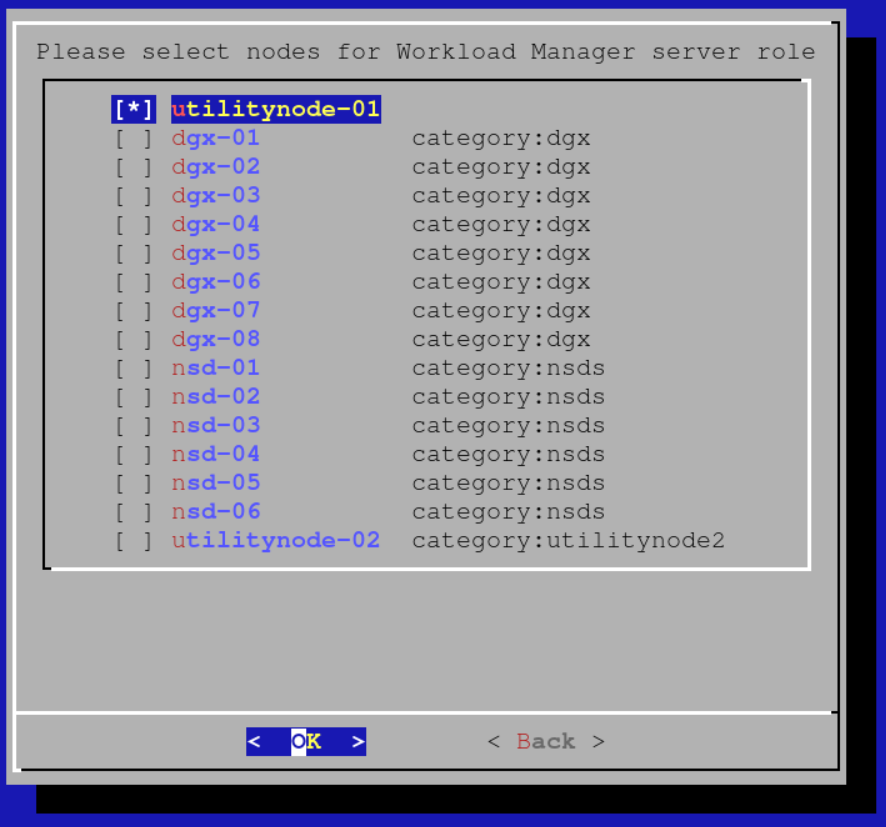
Select your head node as the Slurm server:
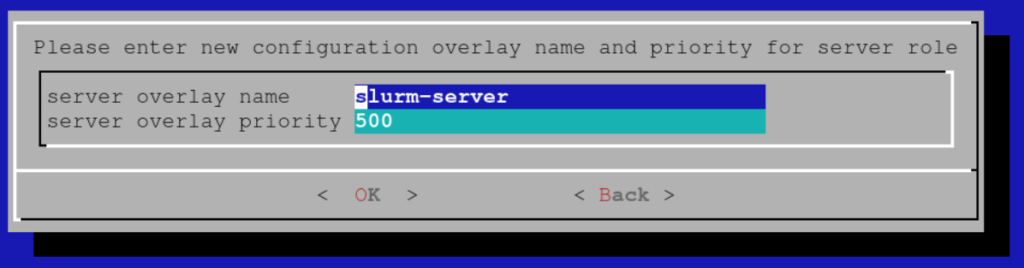
Choose a name for the configuration overlay that is about to be created (the defaults are fine):
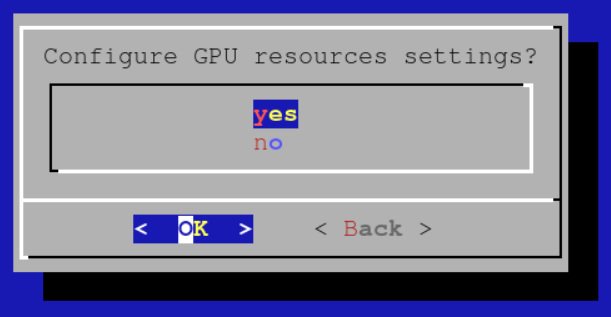
Select Yes to configure GPU resources:
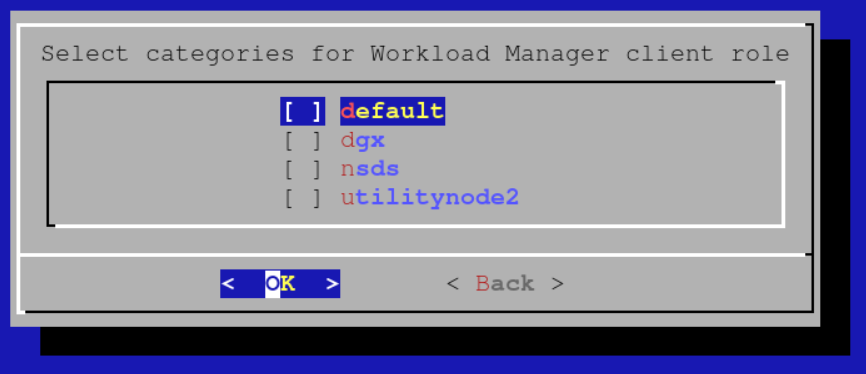
Initially cm-wlm-setup will let you set up Slurm clients without GPUs. Assuming that there are no nodes to be set up without GPUs, unselect all categories and press OK.
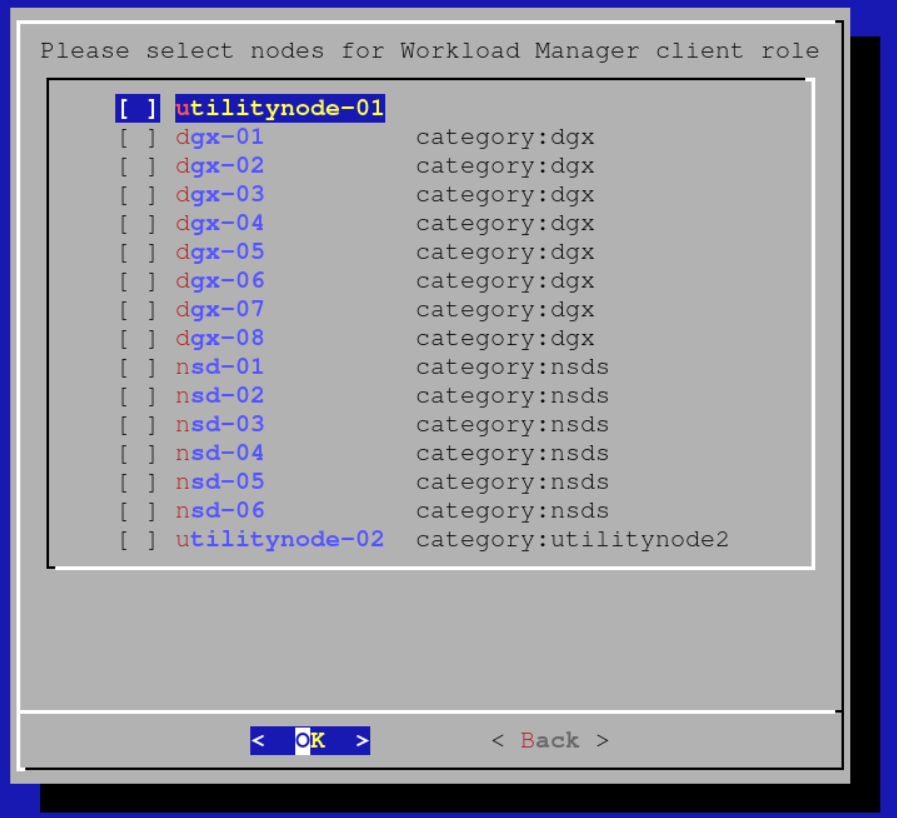
Assuming there are no compute nodes without GPUs, leave all the options unselected at the following screen and press OK:
Choose a suitable name for the configuration overlay of Slurm clients without GPUs (the default is fine):
Choose a suitable name for the configuration overlay of Slurm clients with GPUs (the default is fine):
Select the categories of compute nodes with GPUs that you would like to include in the configuration overlay that was created in the previous step:
Select any additional nodes with GPUs that should be added to the configuration overlay:
Select a priority for the configuration overlay (the default is fine for all practical cases):
Leave the number of slots unconfigured:
Select the category of GPU compute nodes as nodes from which jobs will be submitted. If you have a category of login nodes, you will want to add it as well. We will add the head node in the next screen:
Select additional nodes from where you will be submitting jobs (e.g. head node of the cluster):
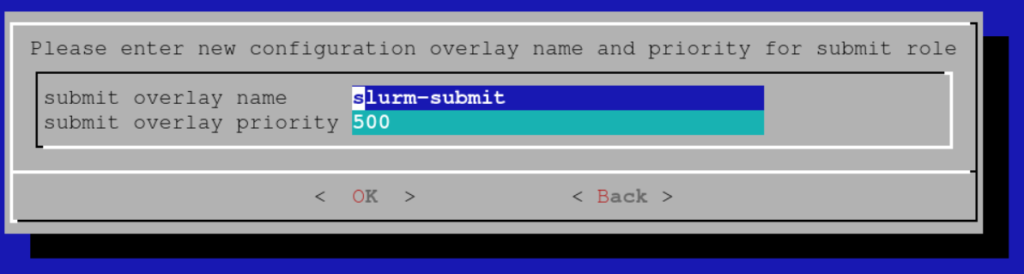
Choose a name for the configuration overlay of submit hosts (the defaults will be fine):
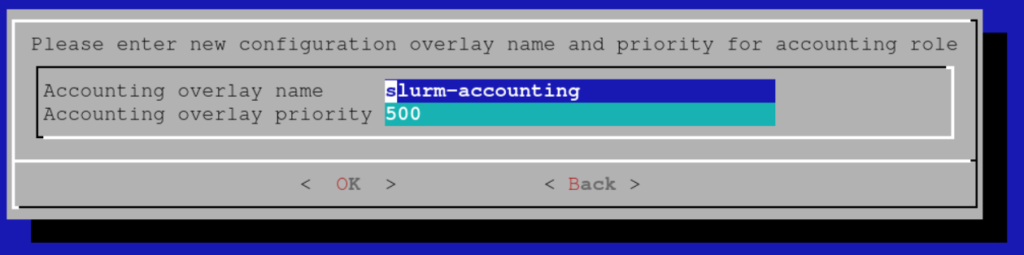
Choose a name for the configuration overlay of accounting nodes:
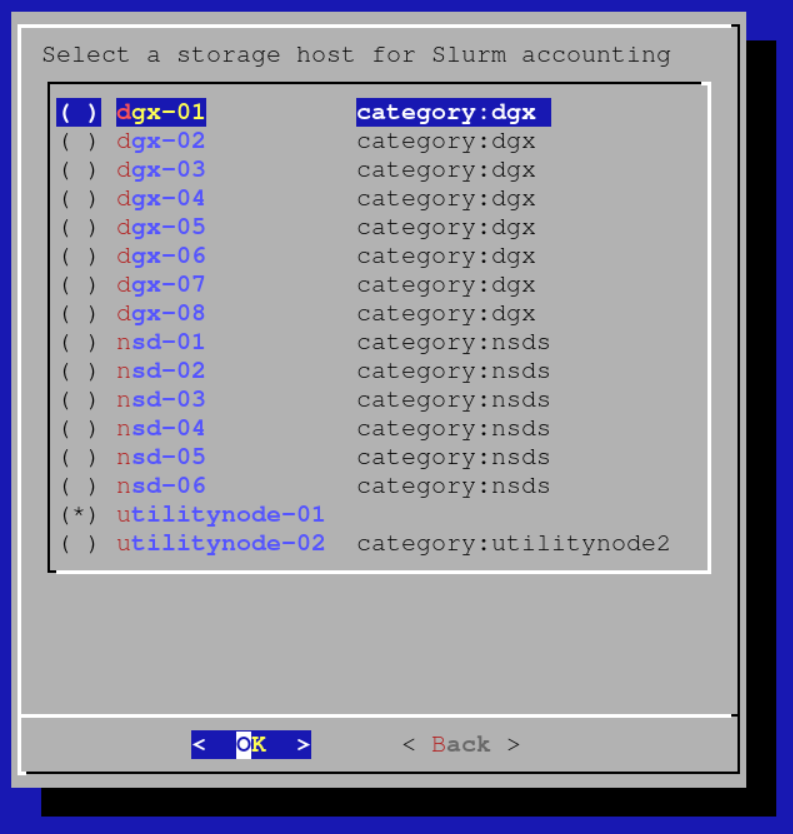
Select the head node as the accounting node:
Add the 8 GPUs in each node as GPU resources that can be requested:
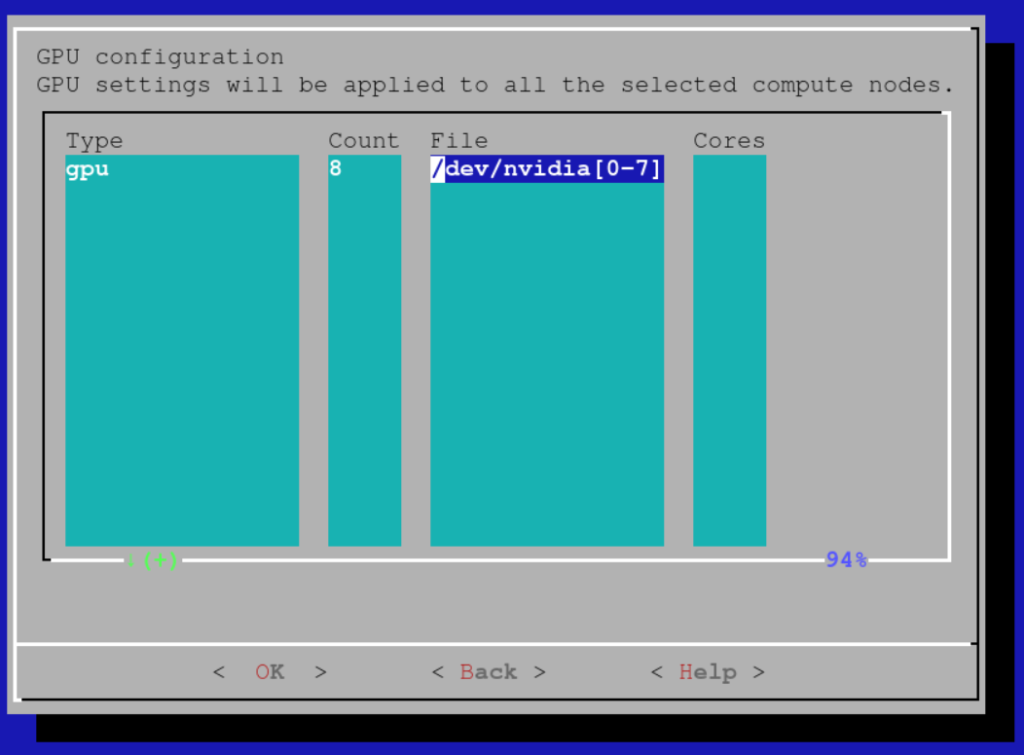
Note that it is also possible to rely on Slurm’s GPU autodetect capabilities. Please consult the Bright documentation for details.
Unless you intend to use CUDA Multi Process Management (MPS), leave the MPS settings empty. If you do intend to use MPS, some additional setup steps will be needed to start/stop the MPS daemon through the prolog/epilog.
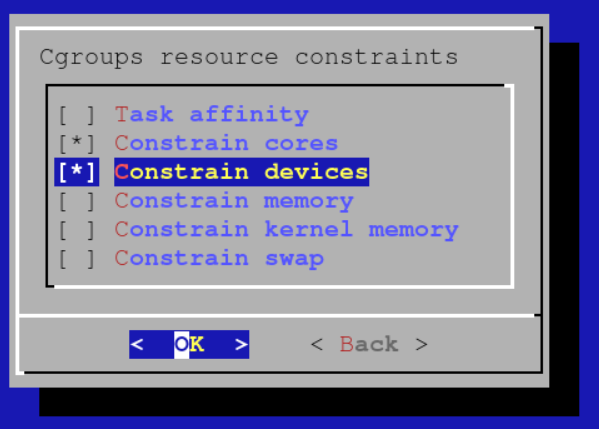
Enable the following cgroup resource constraints to make sure that jobs cannot use CPU cores or GPUs that they did not request:
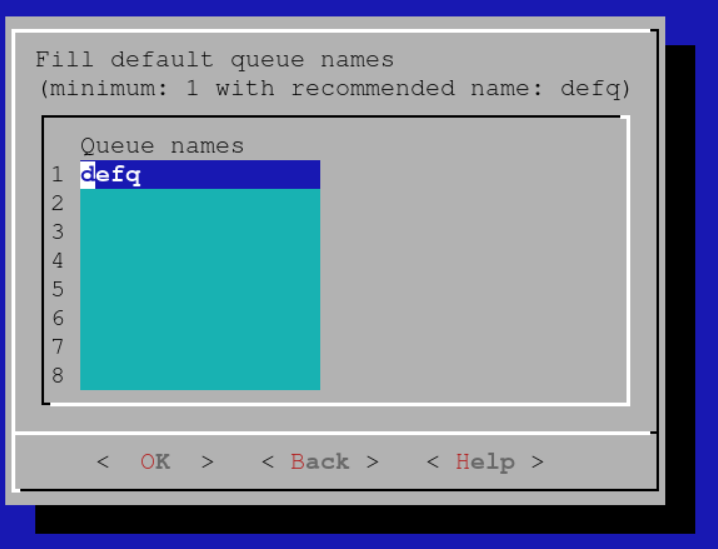
Create a default queue. More queues can always be defined later:
Select Save & Deploy:
Store the configuration for later:
After the setup completes, you will want to reboot all compute nodes using CMSH:
device power reset -c dgxAfter the nodes come back up, you can verify that Slurm is working properly by checking:
[root@utilitynode-01 ~]# sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
defq* up infinite 8 idle dgx-[01-08] By default Slurm is configured to not allow multiple jobs on the same node. To change this behavior and allow (for example) a maximum of 8 simultaneous jobs to run on a single node :
[root@utilitynode-01 ~]# cmsh
[utilitynode-01]% wlm use slurm
[utilitynode-01->wlm[slurm]]% jobqueue
[utilitynode-01->wlm[slurm]->jobqueue]% use defq
[utilitynode-01->wlm[slurm]->jobqueue[defq]]% get oversubscribe
NO
[utilitynode-01->wlm[slurm]->jobqueue[defq]]% set oversubscribe YES:8
[utilitynode-01->wlm[slurm]->jobqueue*[defq*]]% commit
[utilitynode-01->wlm[slurm]->jobqueue[defq]]%
To verify that GPU reservation is working, first try allocating no GPUs:
[root@utilitynode-01 ~]# srun nvidia-smi
No devices were found
srun: error: dgx-06: task 0: Exited with exit code 6
[root@utilitynode-01 ~]#Then try allocating e.g. 2 GPUs:
[root@utilitynode-01 ~]# srun --gres=gpu:2 nvidia-smi
Thu Mar 4 08:50:44 2021
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.102.04 Driver Version: 450.102.04 CUDA Version: 11.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 A100-SXM4-40GB On | 00000000:07:00.0 Off | 0 |
| N/A 30C P0 54W / 400W | 0MiB / 40537MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 1 A100-SXM4-40GB On | 00000000:0F:00.0 Off | 0 |
| N/A 30C P0 53W / 400W | 0MiB / 40537MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+