This article describes how to setup a high availability NFS storage service using Bright.
Architecture
The two NFS servers are directly attached to a shared storage. Only one server should be able to mount the storage at any one time, in order to avoid data corruption. The nodes should have access to the shared storage without interruption as long as one of the two NFS servers is up.
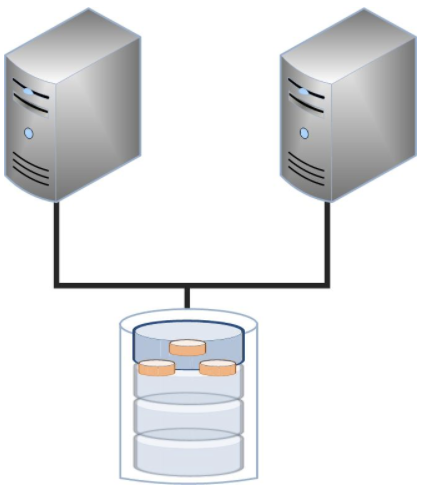
Prerequisites
- You will need CMDaemon revision 29304 or later
- For the DAS device, any type of software RAID is not support and will most likely lead to data corruption
Create the HA group
[root@b70-c6 ~]# cmsh [b70-c6]% partition failovergroups base [b70-c6->partition[base]->failovergroups]% add storage [b70-c6->partition*[base*]->failovergroups*[storage*]]% set nodes nfsserver1 nfsserver2 [b70-c6->partition*[base*]->failovergroups*[storage*]]% commit
Create the shared interface
The shared interface will be used to mount the mount storage across the cluster. This shared interface will be active only on the active server. The interface is an alias interface, which means the name can be arbitrary. A sensible alias for eth0 is eth0:storage, and it is created for both NFS servers, with a virtual shared IP address, like this:
[root@b70-c6 ~]# cmsh [b70-c6]% device interfaces nfsserver1 [b70-c6->device[nfsserver1]->interfaces]% add alias eth0:storage [b70-c6->device*[nfsserver1*]->interfaces*[eth0:storage*]]% set network internalnet [b70-c6->device*[nfsserver1*]->interfaces*[eth0:storage*]]% set ip 10.141.255.230 [b70-c6->device*[nfsserver1*]->interfaces*[eth0:storage*]]% set startif active [b70-c6->device*[nfsserver1*]->interfaces*[eth0:storage*]]% commit [b70-c6]% device interfaces nfsserver2 [b70-c6->device[nfsserver2]->interfaces]% add alias eth0:storage [b70-c6->device*[nfsserver2*]->interfaces*[eth0:storage*]]% set network internalnet [b70-c6->device*[nfsserver2*]->interfaces*[eth0:storage*]]% set ip 10.141.255.230 [b70-c6->device*[nfsserver2*]->interfaces*[eth0:storage*]]% set startif active [b70-c6->device*[nfsserver2*]->interfaces*[eth0:storage*]]% commit
Automatic Failover
By default automatic failover is disabled for HA groups. It can be enabled as follows:
[b70-c6->partition[base]->failovergroups[storage]]% set automaticfailoveraftergracefulshutdown yes [b70-c6->partition*[base*]->failovergroups*[storage*]]% commit
Automatic Failover Dead time
This is the time after which the automatic failover should be triggered. By default it’s set to a very small value (10 seconds). It would be better to increase this dead time to avoid triggering any unnecessary failover events.
[b70-c6->partition[base]->failovergroups*[storage*]]% set deadtime 300 [b70-c6->partition*[base*]->failovergroups*[storage*]]% commit
Exclude the DAS filesystem mountpoints
You will need to exclude the filesystems on the DAS from provisioning operations in order to prevent accidental data loss:
This can be done by modifying the category exclude list:
[bright1->category[nfs]]% set excludelistupdate [bright1->category[nfs]]% commit
etc.
- Exclude list for updates and SYNC install:
- /cmshared/* - /home/* - /apps/* no-new-files: - /cmshared/* no-new-files: - /home/* no-new-files: - /apps/*
- Exclude list for GRAB and GRANBEW:
- /cmshared/* - /home/* - /apps/*
Preventing stale file handles during failover
To prevent stale file hanles the NFS pipe filesystem should reside on shared storage. This way, when the passive NFS server takes over it will be able to maintian the current state. To achive that you need to move /var/lib/nfs to the shared storage and create a symbolig link as follows:
cd /cmshared/ mkdir varlibnfs cp -aR /var/lib/nfs/ varlibnfs/ cd /var/lib mv nfs nfs.OLD ln -s /cmshared/varlibnfs nfs
Since /cmshared is excluded from provisioning operations, this change will require full provisioning.
Other considerations
- For NFSv4 the fsid needs to be set for the root partition. /etc/exports should look like:
/cmshared 172.19.0.0/20(rw,fsid=2,no_root_squash,async) 172.18.0.0/20(rw,fsid=2,no_root_squash,async) /home 172.19.0.0/20(rw,fsid=3,no_root_squash,async) 172.18.0.0/20(rw,fsid=3,no_root_squash,async) /apps 172.19.0.0/20(rw,fsid=4,no_root_squash,async) 172.18.0.0/20(rw,fsid=4,no_root_squash,async) /cm 172.19.0.0/20(rw,fsid=1,no_root_squash,async) 172.18.0.0/20(rw,fsid=1,no_root_squash,async) / 172.19.0.0/20(ro,fsid=0,no_root_squash,async) 172.18.0.0/20(ro,fsid=0,no_root_squash,async)
- Do not assign the storage role to HA NFS servers as it can lead to race conditions with respect to the NFS services
Generic failover script
The generic failover script that is listed here is a “common” script that we design and put somewhere convenient. Using one generic failover script means it is easier to maintain, and in one place. The generic failover script can be called from the user-defined failover scripts. The user-defined failover scripts are composed of commands the administrator wants to run during the failover stages, and the scripts have locations that are defined in CMDaemon. These locations can be set via cmsh, for example:
[b70-c6->partition[base]->failover]% set prefailoverscript /root/myprefscript
The user-defined failover scripts that can use the generic failover script are:
- prefailoverscript
- postfailoverscript
- mountscript
- unmountscript
The generic failover script reads an argument from one of the user-defined scripts that call it, and then executes accordingly. A generic failover script listing is:
#!/usr/bin/python
import os, sys
# check the command line argument:
if (len(sys.argv) != 2) or (sys.argv[1] not in ('mount', 'umount', 'pre', 'post')):
print "Provide 1 argument: mount, umount, pre, post"
sys.exit(1)
import pythoncm
# Connect to the head node with admin certificates
clustermanager = pythoncm.ClusterManager()
cluster = clustermanager.addCluster('https://master:8081';, '/cm/local/apps/cmd/etc/cert.pem', '/cm/local/apps/cmd/etc/cert.key');
# if connection fails exit
if not cluster.connect():
print "Unable to connect"
print cluster.getLastError()
sys.exit(1)
# Find your own node configuration
hostname_pipe = os.popen('hostname')
#hostname = os.getenv('CMD_HOSTNAME')
hostname = hostname_pipe.read()
hostname = hostname.replace('\n', '').replace('\r', '')
print len(hostname)
node = cluster.find(hostname)
if not node:
print "Unable to find node %s" % hostname
sys.exit(1)
# Read current state
f = open('/var/spool/cmd/state')
state = f.readline()
f.close()
print "%s for %s, state = %s" % (sys.argv[0], hostname, state)
# remove CMDaemon fsmounts
def removeFSMount(mountpoint):
print "Remove mount:", mountpoint
node.fsmounts = [x for x in node.fsmounts if x.mountpoint != mountpoint]
# add CMDaemon fsmounts: if the mountoptions is not passed, use defaults
def addFSMount(mountpoint, device, filesystem, mountoptions = 'defaults'):
find = sum([1 for x in node.fsmounts if x.mountpoint == mountpoint])
if find == 0: # duplicate check
print "Adding mount:", mountpoint
fsmount = pythoncm.FSMount()
fsmount.mountpoint = mountpoint
fsmount.device = device
fsmount.filesystem = filesystem
fsmount.mountoptions = mountoptions
node.fsmounts += [fsmount] # append doesn't work for pythoncm objects.list
else:
print "Duplicate mount:", mountpoint
if sys.argv[1] == "pre":
if state == 'SLAVEACTIVE':
print "SLAVEACTIVE";
if state == 'SLAVEPASSIVE':
print "SLAVEPASSIVE";
elif sys.argv[1] == "post":
if state == 'SLAVEACTIVE':
print "SLAVEACTIVE";
# make sure that the mount points are removed from the passive server
if hostname=='nfs01':
print "nfs01"
node = cluster.find("nfs02")
removeFSMount('/home')
removeFSMount('/cmshared')
removeFSMount('/apps')
else:
print "nfs02"
node = cluster.find("nfs01")
removeFSMount('/home')
removeFSMount('/cmshared')
removeFSMount('/apps')
if state == 'SLAVEPASSIVE':
print "SLAVEPASSIVE";
# Add extra mount / exports here
elif sys.argv[1] == "mount":
addFSMount('/cmshared', '/dev/mapper/mpathd1', 'xfs')
addFSMount('/home', '/dev/mapper/mpathd3', 'xfs')
addFSMount('/apps', '/dev/mapper/mpathd2', 'xfs')
# remove extra mount / exports here
elif sys.argv[1] == "umount":
removeFSMount('/cmshared')
removeFSMount('/home')
removeFSMount('/apps')
# All operations done: commit then exit
exit = 0
c = node.commit()
if not c.result:
print "Commit of %s failed:" % node.resolveName()
for j in range(c.count):
print c.getValidation(j).msg
exit = 1
else:
print "Committed: %s" % node.resolveName()
cluster.disconnect()
sys.exit(exit)
Pre-failover script
#!/bin/bash
if [ $(cat /var/spool/cmd/state) == "SLAVEACTIVE" ]
then
echo "ACTIVE"
/cm/local/scripts/generic-nfsserver-ha.py pre
else
echo "PASSIVE"
fi
Mount Script
#!/bin/bash
# make sure that the NFS service is stopped
service nfs stop
# add the required export points and mount the storage
/cm/local/scripts/generic-nfsserver-ha.py mount
# check the available mounts
mounts=`cat /proc/mounts | grep "/dev/mapper/mpathd1" | awk -F" " '{print $1}'`
for i in {1..10}
do
# check if the mount is available.
if [ "$mounts" == "/dev/mapper/mpathd1" ]
then
service nfs restart
exportfs -a
exit 0;
else
echo "Mount point not available? retrying"
sleep 5
fi
mounts=`cat /proc/mounts | grep "/dev/mapper/mpathd1" | awk -F" " '{print $1}'`
done
Unmount Script
#!/bin/bash
NFS=nfs
FUSER=/sbin/fuser
if [ -e /etc/SuSE-release ]; then
NFS=nfsserver
FUSER=/bin/fuser
fi
MAXRETRIES=50
# unmount the storage
doUmount() {
retries=1
while [ $retries -lt $MAXRETRIES ]; do
if grep -q " $1 " /proc/mounts; then
echo "(`date`) Unmount $1 ($retries)"
$FUSER -mk $1
/bin/umount $1
sleep 1
let retries=${retries}+1
else
let retries=${MAXRETRIES}
fi
done
}
# check if the mount point is still available
mountCheck(){
if grep -q " $1 " /proc/mounts; then
echo "Still mounted: $1"
exit 1
fi
}
# stop services offering access to the mount point and call the generic script
# with the umount option
service nfs stop
service rpcidmapd stop
service smb stop
$(dirname $0)/generic-nfsserver-ha.py umount
doUmount /cmshared/varlibnfs/rpc_pipefs
doUmount /cmshared
doUmount /home
doUmount /apps
mountCheck /cmshared
mountCheck /home
mountCheck /apps
echo "remove fsmounts"
Post-failover script
#!/bin/bash
if [ $(cat /var/spool/cmd/state) == "SLAVEACTIVE" ]
then
echo "ACTIVE"
/cm/local/scripts/generic-nfsserver-ha.py post
else
echo "PASSIVE"
fi