Make sure CUDA, git and cmake are installed on the head node of the cluster:
# yum install cuda11.0-toolkit git cmake
Clone the Multi GPU Benchmark (mgbench) repository under a user account (e.g. cmsupport):
su - cmsupport
git clone https://github.com/tbennun/mgbench.git
Load the CUDA environment module:
module initadd cuda11.0/toolkit
module load cuda11.0/toolkit
Build it:
cd mgbench
export CUDA_BIN_PATH=$CUDA_ROOT
sh build.sh
Create a file mgbench.slurm with the following contents:
#!/bin/bash
#SBATCH --nodes=1
#SBATCH -J mgbench
# Remove # from the line below to request 8 GPUs if GPUs are consumable resources in your Slurm configuration
##SBATCH --gres=gpu:8
dir=~/mgbench/job-$SLURM_JOB_ID
mkdir -p $dir
cd $dir
ln -s ../build
sh ../run.shSubmit a number of jobs:
for i in `seq 1 10`; do sbatch mgbench.slurm; done
Each job will take approximately 20m and will run on a single machine. Output can be found in ~/mgbench/job-X (where X is the job-id).
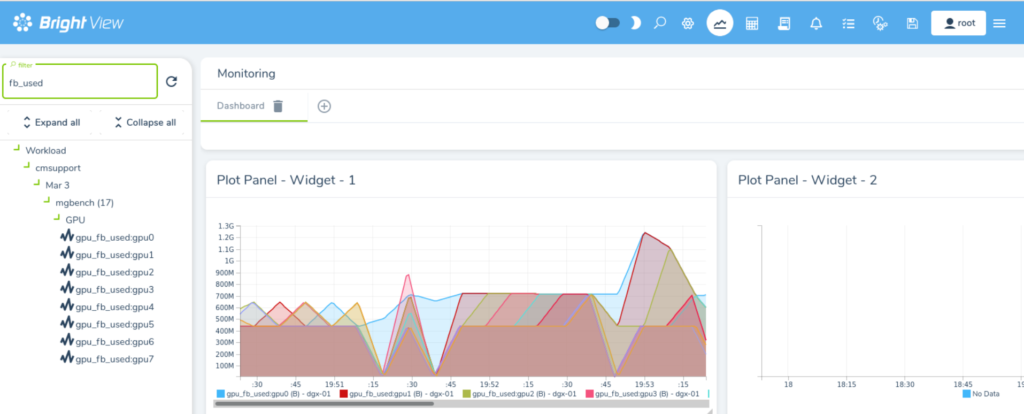
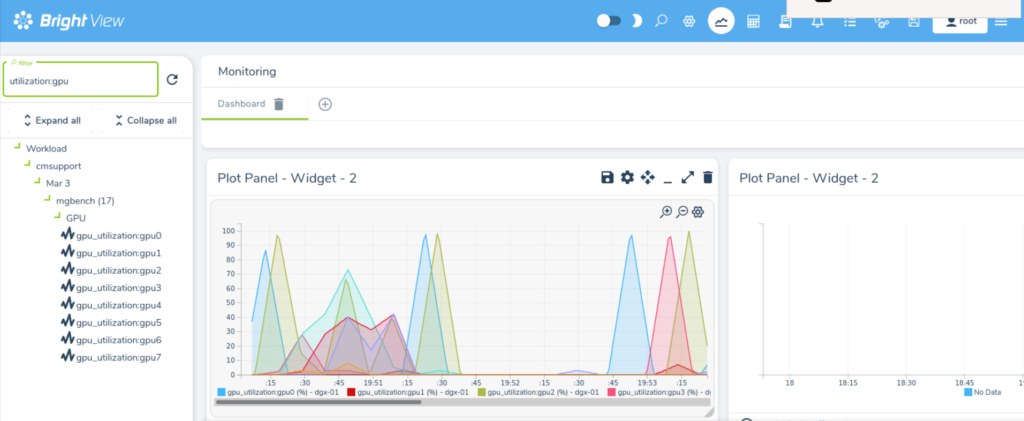
To verify that the GPUs are being utilized for a particular job, you may use Bright View’s job monitoring capabilities. Open the Monitoring view, and select Workload -> cmsupport -> current date -> job id -> GPU. Then visualize the gpu_fb_used and gpu_utilization metrics: